일반적으로 흔히 겪었던 문제들을 한번 짚어봅니다.
-
문제 1: 알림 과부하
우리 Kubernetes 클러스터는 매일 수백 개의 알림을 쏟아냅니다. 파드 재시작부터 노드 리소스 부족까지 다양합니다. 운영팀은 이 알림 폭주 속에서 어떤 문제를 먼저 처리해야 할지 우선순위를 정하기 힘들었습니다. -
문제 2: 표준화된 하지만 수동적인 트러블슈팅
예를 들어 KubePodNotReady 알림이 발생하면 표준 절차는 다음과 같습니다. 아래의 절차는 잘 정립되어 있지만, 매번 수동으로 실행해야 한다는 점이 비효율적입니다.- 파드 상태 확인 (kubectl get pods)
- 상세 정보 확인 (kubectl describe pod)
- 로그 확인 (kubectl logs)
- 필요 시 서비스 재시작
-
문제 3: 신입 팀원의 높은 학습 장벽
새로 합류한 운영 엔지니어는 알림을 받았을 때 어디서부터 시작해야 할지 모르는 경우가 많습니다. 문서가 있더라도 실제 문제 해결 과정에서는 경험 많은 동료의 안내가 꼭 필요했습니다.
이 시점에서, 다음의 고민을 해보면…
운영 전문가들의 트러블슈팅 사고방식을 AI에게 가르쳐서 초기 문제 진단을 맡길 수 없을까?
구체적으로는 다음과 같습니다.
- 알림 내용을 이해하게 하기 — Alertmanager JSON에서 핵심 정보를 추출하도록 만들기
- 어떻게 진단할지 알게 하기 — 알림 유형에 따라 적절한 점검 단계를 선택하도록 하기
- 클러스터를 조작할 수 있게 하기 — 도구를 통해 kubectl 명령을 호출하도록 하기
- 전문적인 조언을 제공하게 하기 — 점검 결과를 바탕으로 진단과 해결책을 제시하도록 하기
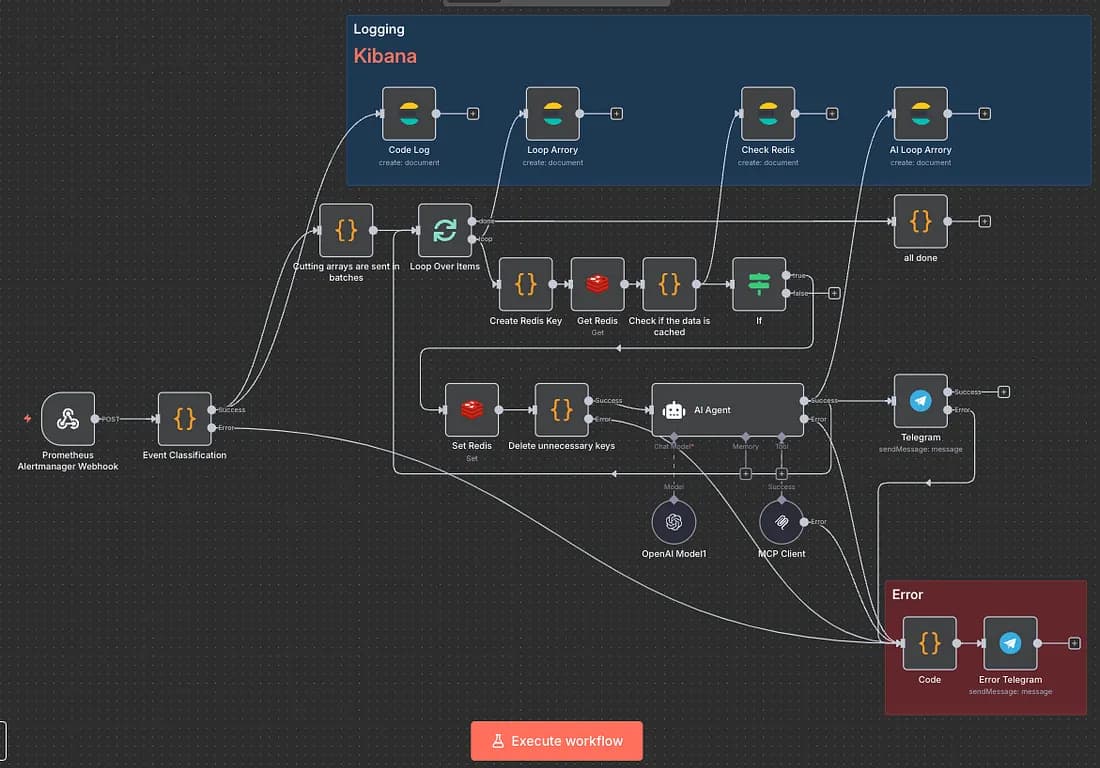
구축한 아키텍처 상세
여러 차례의 조정 끝에, 최종적으로 다음 기술 스택을 선택했습니다.
- 시스템 아키텍쳐
Kubernetes Cluster → Prometheus Server → Alertmanager
↓
n8n Workflow ← OpenAI API ← Custom MCP Server
↓ ↓
Redis Cache Kibana Logs
- 데이터 플로우
Metrics → Alert Rules → Alert Routing → Workflow Orchestration → AI Analysis → Cluster Diagnosis → Automated Reports
-
왜 n8n을 선택했는가?
처음에는 Python 스크립트를 직접 작성하려 했지만, n8n에는 몇 가지 장점이 있었습니다.- 오픈 소스 & 무료: 라이선스 비용 없이 직접 호스팅 가능
- 시각적 오케스트레이션: 전체 처리 흐름이 명확하고 디버깅이 쉬움
- 풍부한 노드 제공: Webhook, HTTP 요청, AI 호출 등 이미 준비된 노드 활용 가능
- 확장 용이성: 새로운 로직을 드래그 앤 드롭으로 쉽게 추가 가능
- 팀 협업: 동료들도 워크플로우를 쉽게 이해하고 수정 가능
-
왜 Custom MCP 서버를 구축했는가?
시중에 Kubernetes MCP 서버가 없었기 때문에 직접 개발했습니다. 주요 기능은 다음과 같습니다.- 17개의 K8s 도구 지원: 기본 kubectl get부터 고급 kubectl top까지
- 보안 제어: 안전한 쿼리와 제한된 동작(예: Deployment 재시작)만 허용
- 멀티 클러스터 지원: 여러 K8s 클러스터를 동시에 관리 가능
- 이중 프로토콜 지원: n8n의 SSE와 다른 클라이언트의 HTTP 모두 지원
-
얼마나 잘 동작하는가?
실제 사례로 보여드리겠습니다. (사례 연구: Pod 장기 NotReady 상태)-
전통적인 접근 방식:
- 알림 SMS 또는 이메일 수신
- 점프 서버에 로그인
- 해당 클러스터로 전환
- kubectl 명령을 수동으로 실행하며 트러블슈팅
- 결과 분석 후 해결 방안 수립
- 수정 작업 실행
- 문제 해결 여부 확인
-
AI 기반 지능형 처리:
시스템이 다음과 같은 알림 JSON을 수신했을 때:
-
{
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "KubePodNotReady",
"cluster": "prod-cluster-***",
"namespace": "production",
"pod": "app-service-***",
"severity": "warning"
},
"annotations": {
"description": "Pod has been in a non-ready state for more than 10 minutes"
}
}
]
}
AI 시스템은 자동으로 다음을 수행합니다.
1 단계: 핵심 정보 추출**
- Alert Type: KubePodNotReady
- Cluster: prod-cluster-***
- Namespace: production
- Pod Name: app-service-***
2 단계: 점검 전략 선택
알림 유형에 기반해, AI는 이것이 “Pod 상태 문제”임을 파악하고 사전에 설정된 점검 절차를 따릅니다.
3 단계: 점검 명령 실행
# 1. Pod 상태 확인
kubectl get pods -n production --show-labels -o wide
# 2. 상태가 비정상이면 상세 정보 확인
kubectl describe pod app-service-*** -n production
# 3. 필요 시 로그 확인
kubectl logs app-service-*** -n production --tail=20
4 단계: AI 분석 및 보고서 생성
────────────────────────────────
🔧 K8s Alert Handler AI
🚨 KubePodNotReady - firing
Start Time: 2025-01-15T10:30:00Z
Cluster: prod-cluster-***
Component: production/app-service-***
Quick Diagnosis:
Pod가 NotReady 상태이며, 컨테이너가 3회 재시작됨
마지막 재시작 시각: 5분 전
에러 원인: 데이터베이스 연결 시간 초과
Analysis Conclusion:
애플리케이션이 데이터베이스에 연결하지 못하고 있으며, 데이터베이스 서비스 문제 또는 네트워크 문제일 가능성이 있음
Recommended Actions:
1. 즉시 데이터베이스 서비스 상태 확인
2. Service 및 Endpoint 구성 점검
3. 필요 시 Pod 재시작 또는 데이터베이스 스케일링 고려
4. 네트워크 정책과 방화벽 규칙 확인
────────────────────────────────
전체 프로세스는 2–3분 내에 완료되며 24/7 지속적으로 동작합니다!
설계한 AI 로직
이 시스템의 핵심은 AI의 의사결정 로직입니다. 프로덕션 환경에서 다양한 알림을 처리할 수 있도록 AI의 시스템 메시지를 세밀하게 조정하는 데 많은 시간을 들였습니다.
지원하는 알림 유형
현재 시스템은 거의 모든 일반적인 문제 시나리오를 포괄하는 45가지 Kubernetes 알림을 지능적으로 처리할 수 있습니다.
클러스터 핵심 컴포넌트 알림 (10)
- AlertmanagerClusterCrashlooping, AlertmanagerClusterDown
- AlertmanagerClusterFailedToSendAlerts, AlertmanagerConfigInconsistent
- AlertmanagerFailedReload, KubeAPIDown
- KubeAPIErrorBudgetBurn, PrometheusBadConfig
- PrometheusTargetSyncFailure, PrometheusRuleFailures
워크로드 관련 알림 (12)
- KubeDeploymentReplicasMismatch, KubeStatefulSetReplicasMismatch
- KubePodCrashLooping, KubePodNotReady
- KubeJobFailed, KubeHpaReplicasMismatch
- KubeHpaMaxedOut, KubeHpaHighUtilization
- KubeHpaFrequentScaling, KubeImagePullBackOff
- KubeServiceEndpointsUnavailable, KubeConfigReloadFailed
컨테이너 및 리소스 알림 (12)
- KubeContainerOOMKilled
- KubeContainerCPUNearLimit
- KubeContainerMemoryNearLimit
- KubeTooManyPendingPods
- KubeCPUOvercommit
- KubeMemoryOvercommit
- KubeQuotaExceeded
- KubeQuotaAlmostFull
- CPUThrottlingHigh
- NodeCPUHighUsage
- NodeMemoryHighUtilization
- NodeSystemSaturation
노드 및 스토리지 알림 (10)
- KubeletDown, KubeNodeNotReady
- NodeFileDescriptorLimit, KubePersistentVolumeErrors
- KubePersistentVolumeFillingUp, KubePersistentVolumeInodesFillingUp
- KubeVolumeMountFailed, NodeFilesystemAlmostOutOfSpace
- NodeFilesystemSpaceFillingUp, KubeStateMetricsDown
인증서 및 모니터링 알림 (5)
- KubeClientCertificateExpiration
- KubeletClientCertificateExpiration
- KubeletServerCertificateExpiration
- KubeStateMetricsListErrors
- Watchdog
각 알림 유형에는 대응되는 점검 전략이 있으며, AI는 알림 유형에 따라 가장 적절한 트러블슈팅 프로세스를 자동으로 선택합니다.
AI 의사결정 로직 설계
-
파라미터 추출 규칙
복잡한 JSON에서 핵심 정보를 찾는 방법을 AI에 알려줍니다.
반드시 추출: cluster, alertType(가장 중요하며, 절대 틀리면 안 됨)
선택적 추출: namespace, pod, container, deployment 등
상태 판단: status가 firing인지 resolved인지 구분 -
문제 분류 로직
45개의 알림을 여러 주요 클래스로 나누고, 각 클래스에 대응하는 점검 전략을 정의했습니다.-
HPA 문제: 먼저 HPA 상태를 확인한 뒤 Deployment를 확인
kubectl 호출은 최대 2회 -
Pod 문제:
먼저 Pod 목록을 확인하고, 그다음 특정 Pod를 describe로 확인, 필요하면 로그 확인
kubectl 호출은 최대 3회 -
Node 문제:
먼저 노드 목록을 확인하고, 그다음 특정 노드를 describe
kubectl 호출은 최대 2회 -
리소스 문제:
kubectl top으로 리소스 사용량 확인
kubectl 호출은 최대 2회
-
-
Rate Limit 보호
이 부분이 중요합니다! AI가 API를 과도하게 호출하지 않도록, 각 알림별로 kubectl 명령 실행을 최대 3회로 제한합니다.- 첫 번째 전략: 결합 조회로 한 번에 개요 정보 수집
- 두 번째 전략: 대상 지정 describe로 문제를 심층 확인
- 세 번째 전략: 로그 조회 또는 기타 보조 정보 확인
-
스마트 스킵 로직
첫 번째 점검에서 상태가 정상으로 판정되면 이후 심층 점검은 실행하지 않아 리소스를 절약합니다.
겪었던 시행착오
-
문제 1: AI의 “과잉 사고”
처음에는 Rate Limit을 두지 않았더니, AI가 수십 개의 명령을 실행하며 K8s API를 과부하 상태로 몰아넣곤 했습니다. 이후 각 알림당 호출 횟수를 제한해 반드시 제한된 횟수 내에서 진단을 완료하도록 했습니다. -
문제 2: 알림 이름 혼동
Alertmanager JSON에는alertname과summary필드가 모두 존재하는데, AI가 이를 혼동하는 경우가 있었습니다. 그래서 시스템 메시지에서 반드시alertname을 기준으로 사용하도록 강조했습니다. -
문제 3: 클러스터 인증 문제
여러 개의 GKE 클러스터를 운영하면서 인증 방식이 제각각이라 어려움이 있었습니다. 최종적으로 MCP 서버에 자동 인증 로직을 추가해, AI가 이 세부 사항을 신경 쓰지 않아도 되게 만들었습니다. -
문제 4: 불충분한 에러 처리
초기에는 kubectl 명령 실패 상황을 고려하지 못해, 권한 문제나 네트워크 문제로 프로세스가 자주 멈추곤 했습니다. 이후에는 완전한 에러 처리와 재시도 메커니즘을 추가했습니다.
실제 성능 결과
3개월간 운영한 결과는 상당히 긍정적이었습니다.
- 데이터 비교
- 알림 처리 시간: 평균 20분에서 3분으로 단축
- 야간 대응: 24/7 자동 처리로 한밤중 호출 사라짐
- 신입 교육: 새로 합류한 동료들이 AI 진단 보고서를 직접 참고하며 학습 가능
- 처리 정확도: 일반적인 문제의 90%에서 올바른 진단 방향 제시
[출처] https://medium.com/@kopp0510/how-i-made-kubernetes-monitoring-smarter-with-ai-b16ff3888e41